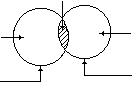UFPr Arts Department
Electronic Musicological Review
Vol. 6 / March 2001
EMR Home - Home - Editorial - Articles - Past Issues
A QUANTITATIVE ANALYSIS OF NATIONALLY SPECIFIC FEATURES OF SONG MELODIES WITH THE USE OF INTERVAL-METRIC CHARACTERISTICS
Irina V. Bakhmutova, Vladimir D. Gusev, Tatiana N. Titkova
This paper addresses the problem of differentiating song melodies by their "nationality" with the use of interval-metric characteristics (IS-characteristics) as a primary description. General properties of IS-characteristics are studied, including the alphabet of IS-codes, combinations of elements with each other. As a secondary description, repeated chains of IS-codes with lengths of 1, 2 or more symbols are considered. An easily interpreted system of integral quantitative factors is suggested that includes the factor of recitativity, the coefficient of asymmetry of the pitch line. This framework enables the formulation of nationally specific features of Russian, French, and American songs in terms of repetitions. Fragments of melodies that are most informative for the classification are thus found. A method of search for the most and least typical representatives of each class of samples is also proposed. The latter serves as basis for outlining boundaries between classes, which are displayed in characteristics of corresponding melodies as "the most French among Russian melodies" or "the most American among French melodies", for example. The most typical representatives of each class can be considered as centers of clusterization of melodies. The presence of such a clusterization in the form of an unconscious adaptation had been explored in a previous work.
Introduction
1. The System of Melody Representation
2. Representation of Texts in Terms of Repetitions
3. Description of the Experiment
4. Properties of IS-characteristics Invariant to the
National Belonging
5. Nationally specific Features of Melodies
6. Nationally specific Intonation Fragments
Conclusion
Notes
References
Acknowledgment
The essential structural components of any kind of text are repetitions. The role of repetitions (melodic, rhythmic, metric) in musical composition is of special significance. The repetition of separate fragments (intonations) in a melody facilitates its learning whilst the melody is enriched by variation. Repetitions are very important for the classification of melodies by genre, style, composer, etc. The representation of musical texts in terms of repetitions proposed by Bakhmutova, Gusev & Titkova (1990) seems to be very convenient for the purpose.
The aim of this paper is to illustrate the classificatory capability of this method of representation with examples that reveal the characteristics which allow the differentiation of melodies by their "national" belonging. This problem has already caught the attention of musicologists and has been studied at the level of rhythmical repetitions (Boroda, 1990). The basis of our work are the interval-metric characteristics of melodies.
The authors’ interest was drawn to this topic through previous work that suggested adaptations (probably unconscious) in sets of Russian and French folk songs. Bakhmutova, Gusev & Titkova (1997) found that, in sets of practically the same number of Russian and French folk songs, the number of "close" (similar to ear) melodies in French songs is much larger than that in Russian songs. This peculiarity suggested the need to find out the specific features of French melodies which distinguish them from Russian and explain such phenomenon. For the present study we extended the material to include also a set of American folk songs. This enabled a more precise differentiation of the common and specific regularities in the sets of melodies.
1. The System of Melody Representation
Musical texts are multidimensional by nature, as every sound can be
characterized by its pitch, duration, and metric accent. It is very difficult
to analyze variations for all three dimensions simultaneously. Following
Zaripov (1983) we represent musical texts
in the form of interval-metric characteristics. The text
![]() consisting
of
consisting
of ![]() notes is
replaced by the sequence of
notes is
replaced by the sequence of
![]() IS-codes.
The IS-code in the
IS-codes.
The IS-code in the
![]() place
place
![]() characterizes the
transition from the
characterizes the
transition from the ![]() to the
to the ![]() tone of melody and is represented by a triplet:
tone of melody and is represented by a triplet:
![]() is the absolute value of the
interval (the number of degrees between the
is the absolute value of the
interval (the number of degrees between the
![]() and
and
![]() tones in the melody); the
sign of
tones in the melody); the
sign of
![]() ("+" corresponds to
an ascending motion of melody pitch line and "–" to descending
one; if
("+" corresponds to
an ascending motion of melody pitch line and "–" to descending
one; if
![]() =0, then the plus sign is
used);
=0, then the plus sign is
used);
![]() is a metric accent of sound
("+" corresponds to transitions from a metrically stronger to a
metrically weaker tone; "–" corresponds to transitions in the
opposite direction). For example, the code 3 + – is interpreted as a jump
of a fourth upwards with simultaneous increase in the metric accent.
is a metric accent of sound
("+" corresponds to transitions from a metrically stronger to a
metrically weaker tone; "–" corresponds to transitions in the
opposite direction). For example, the code 3 + – is interpreted as a jump
of a fourth upwards with simultaneous increase in the metric accent.
The description suggested represents a desirable compromise between two contradictory requirements. On the one hand, it is comprehensive enough in that the melody does not lose its individuality. On the other hand, it is not excessively detailed; in particular, it does not take into account either the duration of sounds or the qualitative (tonal) characteristic of the interval.
2. Representation of Texts in Terms of Repetitions (1)
Let
![]() be the
IS-representation of the melody where
be the
IS-representation of the melody where
![]() in the
in the
![]() position is the triplet
position is the triplet
![]() . The l-long fragment
of text will be called l-gram. In a text of length N – 1
there are exactly (N – l) l-grams separated by a sliding frame of
width l. The number of different l-grams will be denoted by
. The l-long fragment
of text will be called l-gram. In a text of length N – 1
there are exactly (N – l) l-grams separated by a sliding frame of
width l. The number of different l-grams will be denoted by
![]() (it is obvious that
(it is obvious that
![]() ). Let us call the set
). Let us call the set
![]() the frequency
characteristics of the
the frequency
characteristics of the
![]() order of the text T,
where
order of the text T,
where ![]()
![]() is a pair <
is a pair <![]() l-gram (2) and F
(frequency of its occurrence in the text) >
l-gram (2) and F
(frequency of its occurrence in the text) >![]() .
The elements
.
The elements
![]() are conveniently organised
in descending order of F. The full frequency spectrum of the text
T is defined as a set of frequency characteristics
are conveniently organised
in descending order of F. The full frequency spectrum of the text
T is defined as a set of frequency characteristics
![]() where
where
![]() is the length of maximum
repetition in the text T.
is the length of maximum
repetition in the text T.
Thus, the frequency characteristic of the ![]() order is just a set of all possible repetitions of the length l in the
text, which is added to by uniquely occurring l-grams. The full
frequency spectrum contains information on all the repetitions of the length
1, 2, …,
order is just a set of all possible repetitions of the length l in the
text, which is added to by uniquely occurring l-grams. The full
frequency spectrum contains information on all the repetitions of the length
1, 2, …,![]() in the text.
in the text.
The full frequency spectrum can be calculated both for a single text and for
a set of texts
![]() , where m is the
number of texts. When we deal with a set of texts, the concatenation is formed
as
, where m is the
number of texts. When we deal with a set of texts, the concatenation is formed
as
![]() , where * is the separation
sign between different texts and
, where * is the separation
sign between different texts and
![]() is calculated. All
l-grams that have the separator are eliminated from
is calculated. All
l-grams that have the separator are eliminated from
![]() . l–grams can be
ordered by the number of texts in which these l–grams are
presented. This is essential for the choice of the most informative features
that characterize the given class of objects (texts).
. l–grams can be
ordered by the number of texts in which these l–grams are
presented. This is essential for the choice of the most informative features
that characterize the given class of objects (texts).
In a problem of multi-class recognition, each class is represented by its
individual learning set of texts. For simplicity, the number of classes is
taken to be 2,
![]() and
and
![]() are the learning samples for
classes 1 and 2, respectively, and
are the learning samples for
classes 1 and 2, respectively, and![]() and
and
![]() are the frequency
characteristics of the
are the frequency
characteristics of the ![]() order for each class.
Let a set of l–grams common for
order for each class.
Let a set of l–grams common for
![]() and
and
![]() be denoted as
be denoted as
![]() . The l–grams
presented exclusively in one sample are the most interesting for the purpose of
classification. These l–grams can be interpreted as the
set-theoretic complements
. The l–grams
presented exclusively in one sample are the most interesting for the purpose of
classification. These l–grams can be interpreted as the
set-theoretic complements
![]() and
and
![]() to the intersection
to the intersection
![]() of two sets:
of two sets:
![]() and
and
![]() . This is schematically shown
in figure I.
. This is schematically shown
in figure I.
|
|
||
|
|
|
|
Figure I
Formally,
![]() and
and
![]() .
.
If the number of classes k > 2,
![]() is defined as a totality of
l–grams common to at least a pair of samples from
is defined as a totality of
l–grams common to at least a pair of samples from
![]() . Complements are denoted,
respectively,
. Complements are denoted,
respectively,
![]() ,
,
![]() .
.
If the classes of texts under consideration are close enough, the
complements may be weak (with a small number of l–grams). In this
case, some l–grams with a "contrast" property taken from
the intersection
![]() can be used for
classification. The "contrast" property assumes that an l-gram should
have its maximum representation in one of samples (in different melodies) and
its minimum representation in all the remaining samples. Algorithms for
calculations of the frequency spectrum and intersections of two and more
spectra and their complements are based on hashing procedures (Gusev, Kosarev & Titkova, 1975;
Gusev & Titkova, 1994).
can be used for
classification. The "contrast" property assumes that an l-gram should
have its maximum representation in one of samples (in different melodies) and
its minimum representation in all the remaining samples. Algorithms for
calculations of the frequency spectrum and intersections of two and more
spectra and their complements are based on hashing procedures (Gusev, Kosarev & Titkova, 1975;
Gusev & Titkova, 1994).
3. Description of the Experiment
Samples of Russian (![]() , 219 melodies),
French (
, 219 melodies),
French (![]() , 338 melodies), and
American (
, 338 melodies), and
American (![]() , 140 melodies) folk
songs of different genres were analyzed. The total length of melodies in
IS–representation for the first sample is
, 140 melodies) folk
songs of different genres were analyzed. The total length of melodies in
IS–representation for the first sample is
![]() =9197, for the second sample,
=9197, for the second sample,
![]() =18641, and for the third,
=18641, and for the third,
![]() =7779 symbols (each symbol is
a triplet corresponding to the IS–code).
=7779 symbols (each symbol is
a triplet corresponding to the IS–code).
In the course of the experiment full frequency spectra were obtained for the
samples
![]() , their intersection
, their intersection
![]() , and complements
, and complements
![]() . Based on the frequency
spectra some integral numerical values characterizing each of three samples on
the whole were obtained. Some examples are given below.
. Based on the frequency
spectra some integral numerical values characterizing each of three samples on
the whole were obtained. Some examples are given below.
(1) The Recitativity factor
![]() shows the frequency of
occurrence in sample
shows the frequency of
occurrence in sample
![]() of the
B-IS–codes with
of the
B-IS–codes with
![]() , which corresponds to the
repetition of a same pitch (
, which corresponds to the
repetition of a same pitch (![]() or
or
![]() ). Formally, for the sample
). Formally, for the sample
![]() with the total number of
IS–codes
with the total number of
IS–codes
![]() ,
,
![]() , where
, where
![]() is the frequency of
occurrence of the code
is the frequency of
occurrence of the code
![]() in
in![]() .
.
(2) The Mean (for all melodies from![]() )
length of the maximum (for each melody) recitative chain
)
length of the maximum (for each melody) recitative chain ![]() indicates the clusterability level of recitative elements inside the melody .
Formally,
indicates the clusterability level of recitative elements inside the melody .
Formally,
![]() , where
, where
![]() is the length of maximum
series of IS–codes with
is the length of maximum
series of IS–codes with
![]() =0 in the melody
=0 in the melody
![]() and m is the number
of melodies in
and m is the number
of melodies in
![]() .
.
(3). The coefficient of asymmetry of the pitch line
![]() indicates an averaged
difference in steepness of the growing and drop of individual peaks forming the
melodic contour. Averaging is done for all the peaks inside the melody and for
all the melodies of the sample. Formally,
indicates an averaged
difference in steepness of the growing and drop of individual peaks forming the
melodic contour. Averaging is done for all the peaks inside the melody and for
all the melodies of the sample. Formally,
![]() , where
, where
![]() is the mean value of the
interval for ascending motion and
is the mean value of the
interval for ascending motion and
![]() is the mean value of the
interval for the descending motion. They are calculated as follows:
is the mean value of the
interval for the descending motion. They are calculated as follows:
![]()
![]() ,
,
where
![]() is the number of
IS–codes of the sample
is the number of
IS–codes of the sample
![]() with values
with values
![]() and
and
![]() , respectively, and
, respectively, and
![]() is the number of
IS–codes with values
is the number of
IS–codes with values
![]() and
and
![]() .
.
These and a number of other integral characteristics convey important information on the general differences amongst the samples. Local characteristics that enable judgements on the "national" belonging of certain melodies will be considered in Section 6.